데이터 부족은 기업도 마찬가지...갈수록 중요해지는 인간 역할
GPT-4o'나 '제미나이' 같은 대형언어모델(LLM)의 학습을 위한 데이터가 고갈된다는 이야기는 자주 등장했습니다.
지난 4월에는 현재 인터넷에 존재하는 데이터만으로는 2년 내 AI 모델 성능을 높이는 데 한계를 맞을 것이라는 주장이 나왔습니다. 반면 최근에는 현재 성장률로는 5년 정도는 양질의 텍스트 데이터를 공급할 수 있다는 분석도 등장했습니다. 여기에 저작권 인식이 높아지며 웹 크롤링 차단이 늘어나는 등 범용 LLM의 학습 데이터가 줄어든다는 것은 사실입니다.
그러나 이런 문제는 맞춤형 모델을 사용하는 기업도 비슷한 상황이라는 보고서가 등장했습니다. 글로벌 데이터 제공 업체 에펜(Appen)은 최근 데이터 소싱, 정리 및 라벨링과 관련된 병목 현상이 전년 대비 10% 증가했으며, 이 때문에 효과적인 AI 모델을 구축하고 유지하는 것이 어렵다고 발표했습니다.
이번 연구는 500명이 넘는 미국 IT 의사결정권자를 대상으로 설문 조사한 결과입니다. 이에 따르면 기업의 생성 AI 도입은 지난해 17% 증가했지만, 이제는 데이터 준비와 품질 문제로 점점 어려움을 겪는 것으로 나타났습니다.
데이터의 중요성은 이제는 상식에 가까운 이야기입니다. 그럼에도 다시 이 이야기가 등장한 것은 대부분 기업(86%)이 적어도 분기별 한번은 모델을 미세조정, 성능을 업그레이드하기 때문입니다.
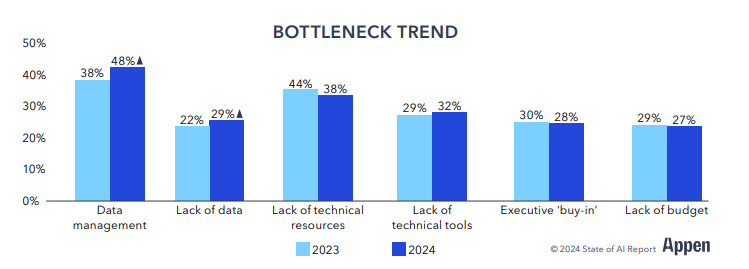
이 과정에서 다양성과 확장성을 갖추고 편향은 줄어든 고품질 데이터의 필요성은 더욱 강조되며(97%), 데이터 전문 기업을 찾는 경우가 점점 늘어나고(93%) 있습니다. 하지만 이런 데이터 매니지먼트에 어려움을 느끼는 기업이 2022년 38%에서 2023년에는 48%로 늘어났다는 내용입니다.
따라서 AI 개발에서 데이터 정확도는 2021년 이후 약 9% 포인트 떨어졌다고 지적했습니다. 이는 AI 시스템이 더욱 복잡해지고 데이터 라벨링이 점점 정교해지고 도메인 전문성이 필요해진 데 따른 것이라고 합니다.
(사진=에펜)
결국 데이터 구축이나 라벨링 과정에서 인간의 역할이 점점 강조된다는 내용입니다. 응답자 80%는 인간의 통찰력이 AI 시스템을 개선하는 핵심이라는 데 동의했습니다. 잘 교육된 인원으로 데이터를 평가하고 라벨링하며 모델을 개선하는 것이 시스템의 발전만큼 더 중요해졌다는 말입니다.
이와 관련 최근에는 모델의 답변을 확인하고 피드백을 주는 '모델 트레이너'가 새로운 고소득 직군으로 떠오른다는 소식도 전해졌습니다.
여기에는 박사 학위자를 포함해 과학자나 전문가가 포함된다는 설명입니다.
최근 오픈AI에서는 대학원생 수준으로 추론할 수 있다는 'o1'을 선보였고, 인간 지시없이도 알아서 업무를 처리하는 AI 에이전트가 서서히 등장하고 있습니다.
이에 따라 언젠가는 인간이 할 일이 크게 줄어들 것이라는 지적도 나옵니다.
그러나 데이터와 AI 검증만큼은 인간의 역할이 더욱 강조되는 분위기입니다. 올해 초에도 AI가 20년 내 모든 작업에서 인간을 능가할 확률은 50%라는 연구가 등장했는데,
이 중 가장 마지막까지 남을 인간의 직업으로는 'AI 연구'가 꼽혔습니다. AI의 성능을 평가하고 개선하는 것은 끝까지 인간의 몫이라는 내용입니다.
출처 : AI타임스(https://www.aitimes.com)