
AMD Instinct MI325X는 GPU 구성 측면에서 MI300X와 유사하지만, 전력 관리 및 주파수, 전압 곡선이 최적화되어 컴퓨팅 성능을 높였고, 더 빠르고 용량이 큰 HBM3E 메모리와 결합되었습니다. MI300X는 192GB HBM3 메모리를 특징으로 하는 반면, MI325X는 256GB HBM3 메모리를 가지고 있습니다.
이 HBM3 메모리는 클럭이 더 높고, 6TB/s 이상의 피크 대역폭을 제공하며, 이는 MI300X의 5.3TB/s에서 13% 증가한 수치입니다. 그러나 256GB는 AMD가 처음 발표했던 288GB보다 32GB 줄어든 것입니다. Advancing AI 행사에서 AMD 관계자들은 MI325X의 목표가 다소 변경되었으며, 시장 기회를 가장 잘 대응하기 위해 메모리 용량을 약간 줄이기로 결정했다고 밝혔습니다.
상대적으로 높은 주파수(정확한 숫자는 없지만)와 추가 메모리 및 메모리 대역폭은 효과적으로 MI325X의 컴퓨팅 성능을 향상시킵니다. GPU에 더 많은 데이터를 가깝게 두고, 이 데이터를 훨씬 빠르게 칩으로 공급함으로써, GPU 리소스가 보다 효과적이고 효율적으로 사용되어 실제 성능이 향상됩니다.

Instinct MI325X의 후속 모델인 Instinct MI355X도 오늘 공개되었습니다. MI355X에 대한 세부 사항은 부족하지만, Computex에서 제공된 초기 힌트와 일치하는 몇 가지 세부 사항이 공개되었습니다. Instinct MI355X는 새로운 GPU 아키텍처인 CDNA 4를 기반으로 하며, 내년 하반기 중에 출시될 예정입니다. 현재 세대의 CDNA 3 기반 MI300X 패밀리와 비교하여 MI355X는 더 발전된 3nm 공정 노드를 사용하여 제조되며, 288GB의 HBM3E 메모리를 특징으로 하고 새로운 FP4 및 FP6 데이터 타입을 지원합니다.
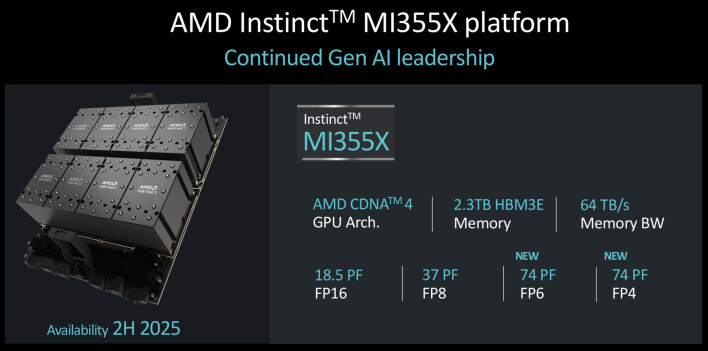
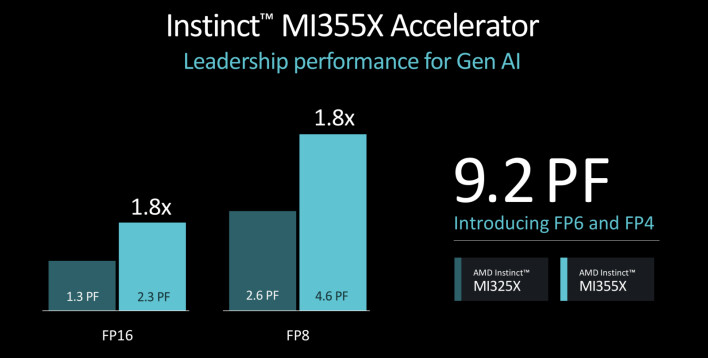
AMD는 Instinct MI355X가 FP8 및 FP16 데이터 타입과 비교하여 CDNA 3 대비 AI 추론 성능이 최대 1.8배 향상될 것이라고 주장하고 있지만, 그 소프트웨어와 알고리즘은 자주 발전하기 때문에 성능 목표는 지속적으로 변화할 가능성이 높습니다.
AMD는 차세대 아키텍처 기반의 새로운 Instinct 가속기를 공격적인 연간 리듬으로 출시할 계획도 재확인했습니다. 이는 CDNA 5 기반의 가속기 시리즈가 2026년 어느 시점에 출시될 것임을 의미하지만, AMD는 MI400이라는 상표명 외에는 구체적인 세부 사항을 제공하지 않았습니다. 또한 AMD의 소비자 및 데이터 센터/AI GPU 아키텍처 통합 계획이 있기 때문에, 향후 제품들이 다소 변화할 가능성이 높습니다.
새로운 AMD Pensando DPU 네트워킹 기술
오늘날 AI 데이터 센터의 모든 시스템 간 빠르고 안정적인 연결의 중요성은 무시할 수 없습니다. 프런트 엔드는 AI 클러스터로 데이터를 이동하고, 백엔드는 가속기와 클러스터 간의 데이터 전송을 처리합니다. 프런트 또는 백 엔드가 병목 현상에 빠지면, AI 시스템 내의 CPU 및 다양한 가속기에 최적의 데이터를 공급하지 못해 활용도가 낮아지고 수익 손실이나 서비스 품질 저하로 이어질 수 있습니다.
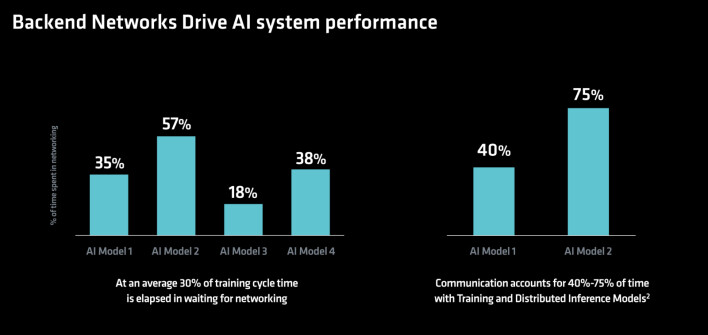
바로 그 점에서 AMD의 Pensando DPU(데이터 처리 장치)가 등장합니다. 프런트 및 백엔드 네트워크를 가속화하고 효율적으로 관리하며, 시스템의 CPU를 오프로드하기 위해 AMD는 프런트 엔드용 Pensando 살리나 DPU와 산업 최초의 초고속 이더넷 컨소시엄(UEC) 준비된 AI NIC인 Pensando 폴라라 400을 소개했습니다.

AMD Pensando 살리나 DPU는 이 회사의 고성능 프로그래머블 DPU의 3세대 제품으로, 400G 처리량을 지원해 2세대 "엘바" DPU 대비 성능과 대역폭이 두 배로 증가했습니다.


AMD Pensando 폴라라 400은 AMD P4 프로그래머블 엔진으로 구동되며, 회사는 이를 업계 최초의 UEC 준비 완료 AI NIC이라고 주장하고 있습니다. AMD 펜산도 폴라라 400은 차세대 RDMA 소프트웨어를 지원하며, 고속 네트워크의 신뢰성과 확장성을 최적화하고 향상시키기 위한 여러 새로운 기능을 제공합니다.